Synapse: PRISMA's Psychedelic Science Archive
About Synapse
The field of psychedelic science is a dynamic and rapidly expanding discipline. However, navigating its vast and growing body of literature can be a significant challenge, especially for an emerging research ecosystem like the one in Puerto Rico. To address this, we are developing a psychedelic literature database. This project aims to accelerate the development of new research and knowledge products by making the most relevant scientific literature more accessible to researchers in Puerto Rico and the wider Latin American community.
Justification: A Catalyst for Research
For an underdeveloped discipline like psychedelic science in Puerto Rico, a literature review can be a daunting and time-consuming task. Our project directly tackles this challenge by streamlining the process of finding and synthesizing information. By providing a curated and easily searchable database, we free up researchers to dedicate more time to designing studies and analyzing results. This initiative is designed to empower our community by providing a foundational tool that fosters more efficient and impactful research.




Our Approach: Methodology and Design
Our approach is built on a two-phase development methodology that leverages automation and machine learning to make the database a powerful and intelligent tool.
The first phase, lasting three months, focuses on building a Python-based scraper. This tool will systematically find relevant papers based on keywords from a variety of sources. Once the papers are identified, a machine learning algorithm will categorize the articles under descriptive labels, making it easier to sift through the content and find specific areas of interest.
The second phase, also spanning three months, involves the development of an AI summarization workflow. For open-source papers, AI will be used to generate concise summaries. In cases where papers are behind a paywall, we will solicit the full text from the authors. If the full paper is not obtained, the database will display the abstract in its place, ensuring transparency about the information's source and scope.
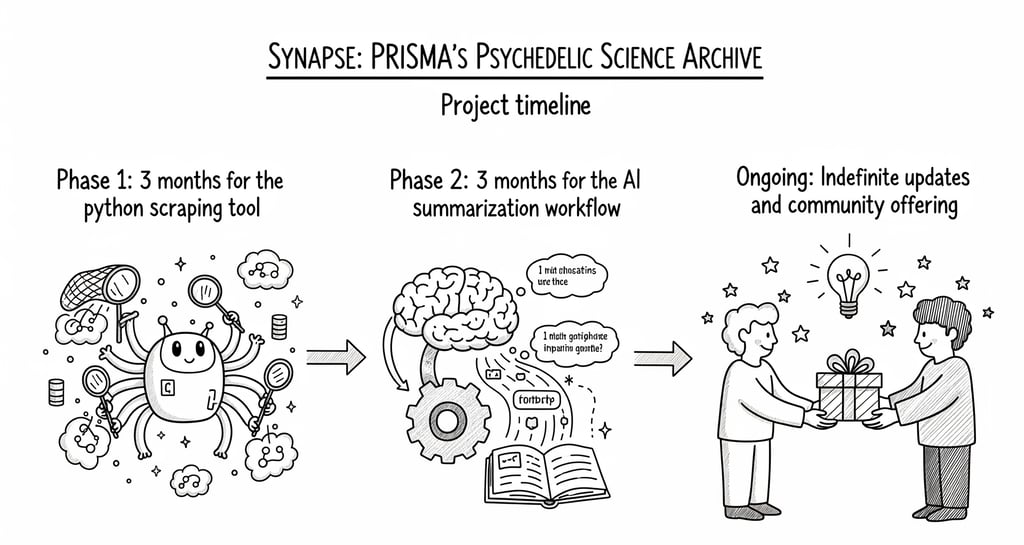
Project Timeline and Status
This project's development is structured to provide an accessible and valuable resource to the community as quickly as possible. The initial development phase is projected to take a total of six months. We will dedicate three months to building and refining the Python scraping tool, followed by three months to develop the AI summarization workflow. Following this initial six-month period, the project will transition into an indefinite community offering, with continuous updates to ensure the database remains the most up-to-date and relevant resource available.